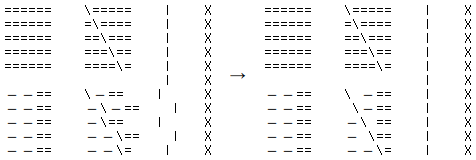
Over the past few years I've spent way more time on text-based user interfaces than what can still be considered healthy, and I'd like to discuss some aspects of their creation in the context of the *nix environment.
All things considered, I've had enough of terminals, and I even started to find monospace fonts hard to read, so while this stays a valid means to write all sorts of applications, I'm going to be focusing on GUIs more in the future instead of trying to circumvent the limitations of something coming from the 70s.
I apologise in advance for any factual errors in the article, it is very broad in scope.
In order to be able to store any text in the computer, you need a well-defined character set and a way to encode it. Historically, many encodings have been in use, most of them based on ASCII and each covering a slightly different charset, assigning different values to the narrow upper half of a byte's value range. Until, of course, Unicode finally happened in the early 90s, a solution to the plethora of ways one could interpret a stream of bytes. Well, sort of, as you still need to know that it is being used in the first place, and which encoding of it, or at least be able to make an educated guess. Anyway, its character set was designed to be a superset of all the other charsets in use and more.
The C language also has something that may be used to represent a character from any supported encoding or charset on the system—so called wide characters. Unfortunately, this is not necessarily the same thing as Unicode, unless __STDC_ISO_10646__ is defined on the system. In fact, the real purpose of this concept is to coalesce units in multibyte strings, and to do something about those ugly Asian shift encodings. But it is perfectly fine for FreeBSD, NetBSD and others to make it locale-dependent (again because of some East Asian nonsense). I'm not so sure if it's okay for Windows to use UTF-16, where you may need two units to represent a codepoint, but at least it's not UCS-2 anymore and they can't even really change that width because of backwards compatibility. Luckily, at least glibc/Linux is the sane one here and gives us the full UCS-4.
Why am I talking about this? I want you to be aware of the mess this is, and that you might not want to pick these wide characters for internal representation of text—serious applications going with their needs beyond the current locale's encoding will probably want to create iconv converters between that encoding, be it the wide or multibyte form, and UTF-8/UCS-4, and only use the locale's encoding when I/O is needed. That is, only to communicate with the user, interpret filenames and maybe a few other things like reading out the user's full name info from /etc/passwd. You can also ignore legacy encodings altogether like e.g. Neovim does, which is not completely unreasonable in this age.
So let's assume for simplicity that everything is UTF-8 and UCS-4. Are we free of trouble now? Of course not. Enter the world of full-width/double-wide characters! Again, we can safely blame Asians, as they're even the ones behind the Emoji nonsense. The original problem though was that characters such as 日本語 were a bit too wide to be represented by just one cell on your typical terminal, so they had to use two. (Cells, not terminals.) The way you tell a half-width character from a full-width one is through the standard C library function wcwidth. And you need to do this for every single character of questionable origin you put on the screen. There go simple alignment algorithms. As if handling tabs wasn't enough.
It also creates some interesting problems. For example, there must be an agreement between the terminal's wcwidth, font glyphs, your libraries' wcwidth, and your application's wcwidth. What's more, ncurses gets very confused if you get the crazy idea to write in the middle of a character on a window, which is a real concern when you do something like the painter's algorithm, drawing one thing on top of another:
#include <locale.h>
#include <ncurses.h>
int main(int argc, char *argv[]) {
if (!setlocale(LC_ALL, "") || !initscr() || curs_set(0) == ERR)
return 1;
// Replacing a full-width character with a half-width one breaks ncurses
for (int i = 0; i < 5; i++) {
mvaddwstr( i, 0, L"======");
mvaddwstr( i, 10, L"======");
mvaddwstr( i, 10 + i, L"\\");
mvaddwstr(6 + i, 0, L"ーー==");
mvaddwstr(6 + i, 10, L"ーー==");
// However this fixes it: wnoutrefresh (stdscr);
mvaddwstr(6 + i, 10 + i, L"\\");
}
// The first vertical line ends up misaligned, the second one is fine;
// interestingly, just calling wnoutrefresh() wouldn't be enough
for (int i = 0; i < 11; i++) mvaddwstr(i, 20, L"|");
refresh();
for (int i = 0; i < 11; i++) mvaddwstr(i, 25, L"X");
refresh(); getch(); endwin(); return 0;
}
This program produces the output on the left, unless you uncomment the magical statement, which somehow makes ncurses suddenly realise that full-width characters exist, and replace the other half of overwritten wide characters with a space, as seen on the right side:
Last but not least, you must be aware of non-spacing characters that modify their surroundings.
Others have written about Unicode shenanigans, too.
Originally there weren't that many things you could send through a terminal: basic ASCII including the control range, and a few special keys. The kind-of-famous VT100 didn't even have an Alt/Meta key:
Eventually someone figured out that the normally unused top bit of a character, given eight bits in a byte, could be used to relay the Meta key, and when it became obvious that people wanted to use that bit for their fancy encodings, realised that perhaps prepending an Escape (control character 27) instead could also work. So now we have two ways of doing it and a source of confusion in dated software like XTerm and GNU Readline.
Similarly, no one anticipated today's desires to handle wild combinations such as Ctrl-Shift-<letter>, and to this day Ctrl is being translated by terminals as that letter with the top three bits of its ASCII value grounded, losing the Shift information in the process.
There also used to be all sorts of incompatible models of terminals, sending different codes for the same keys, and requiring different control sequences, prompting the creation of the termcap and later terminfo library, for without them you would be unable to discern what it is you are receiving over the wire. In fact, while VT100 has become a de facto standard, even modern virtual terminals like xterm and urxvt still can't agree on all their codes. This is typically handled by ncurses, which also consequently becomes somewhat constrained by their specifics, as well as by its own standardised API.
But not even ncurses will save you from having to accept both ^H (ASCII 8) and ^? (ASCII 127) explicitly besides the "canonical" KEY_BACKSPACE, since terminfo likes to be wrong.
Realising some of the limitations, Paul Evans has created libtermkey, which is being used today in Neovim as well as other software, and provides a better alternative. Obviously you're going to need a terminal that can send the extended key codes in order to make use of those. Unfortunately the library is UTF-8-only, causing me to create my termo fork in order to use it in my employer's legacy encoding-using system. It has some other slight improvements, too, for things I care about.
There are three basic modes you can enable—1000 will only get you
clicks, 1002 will get you drags, and 1003 spams you with all mouse movement.
However, to get the last two ones, ncurses either ridiculously wants you to
change your TERM to something like xterm-1002, or you
need to write a magical sequence of e.g. "\x1b[?1002h" straight to
the terminal, in addition to setting REPORT_MOUSE_POSITION.
(There's also a related 1004 mode that reports focus in/out events, slowly getting wide support. It may be useful for changing the colour of selections when the window is defocused, to mimic GUI toolkits.)
Next, if you want to get extended mouse coordinates at all (column ≥ 223),
there are three submodes you can opportunistically enable—the
broken 1005 that tried to misuse UTF-8, the fixed SGR 1006, and rxvt-unicode's
custom 1015. The terminfo database is slowly starting to auto-enable the 1006
mode where it's supported. Otherwise you need to at least output a magical
sequence of "\x1b[?1006h". That should work with most
current terminals at least. rxvt-unicode before the fairly recent version 9.25
wouldn't support the 1006, instead standing by its own 1015, which aimed to fix
1005 and predated the 1006. To enable that, you had to check TERM
manually in your application, and use a different magical sequence of
"\x1b[?1015h". urxvt didn't support DECRQM either, so you couldn't
jusk ask the terminal the usual way.
Mouse was historically broken in ncurses. At least between the years of 2012 and 2014, it was basically unusable because of its unreliability, which luckily seems to be fixed now. Yet I've just discovered that it crashes with rxvt-unicode if you keep clicking outside the coordinate range. Therefore, to get the best results, I can again suggest libtermkey, or even better my fork termo, as I focused on good mouse support.
In theory, there's nothing to do here. Selection and consequently copying is handled by the terminal, provided the text can be seen in its entirety. Pasting, however, can be a problem when you don't want to accidentally pass several hundred lines of something through a chat client, when you want to avoid autoindent in a text editor, or when you want to avoid parsing arbitrary data as non-letter keys.
One not quite reliable way of detecting whether the user is pasting something
is via timing. Recently though, a better means of solving this problem has
gained wide support: the bracketed paste mode. Just enable it via
"\x1b[?2004h" and all pasted input will come wrapped in a pair of
"\x1b[200~" and "\x1b[201~". Hopefully, that input
itself won't be so evil as to contain a premature, fake end marker, doing
whatever this was supposed to protect the user from in the first place.
Although I suppose you can combine this feature with timing…
Of course, the bracketed paste mode is way too new for ncurses to concern
itself with. At most you can enable it opportunistically, detect a paste using
define_key("\x1b[200~", …), and wait for the end marker
yourself, but the mode will stay on in case of a crash, which ncurses otherwise
handles automatically. Not even libtermkey does anything about this yet, and
likely never will.
Note that some terminals also recognise a
"\x1b]52;selections;base64\a" sequence (OSC 52) that
can be used both as a request to retrieve current clipboard contents as well as
to change them, but it may very well be disabled by default, since it poses a
mild security issue.
Forget about it. Sixel graphics are essentially only supported by xterm and mlterm, the private extensions of kitty, iTerm2 and urxvt have similarly limited use, and w3mimgdisplay is a horrible hack where you invoke an external application to paint over the terminal emulator's X11 window, which of course won't work everywhere. And certainly not over ssh in case that (a) there's no X11 forwarding, (b) the WINDOWID environment variable isn't passed through, or (c) w3mimgdisplay isn't present on the remote side of the connection. Pixel alignment needs to be fine-tuned by hand. The remaining methods used by Ranger aren't any better.
What sort of remains is Unicode half-blocks, giving an almost square grid, or quarter-blocks, with only two colours per each four-pixel group:
▀▄▄▀ ▄██▄ ▚▞ ▟▙ ▝▛ ▌▐ ▌▐▘ ▐ ▛ ▙▐ ▘▝▛ ▜▘▗▀▖▗▀▖ ▐ ▌▐▘▐▀ ▛▘▐ ▌▐ ▄▀▀▄ ▀██▀ ▞▚ ▜▛ ▌ ▛▜ ▌▗▌ ▐ ▟ ▌▜ ▌ ▐ ▝▄▘▝▄▘ ▝▄▘▗▌▐▙ ▛ ▝▄▘▐▄
It somewhat works for showing text in large, friendly letters—five pixels is already high enough for most latin characters, including 8 and B (though remember to add two pixels for padding). Not that I could imagine any sane use case for this. But maybe QR codes are worth a thing, for when you want to transfer URLs or other data to a mobile device:
█▀▀▀▀▀█ ▄▄ ▄█▄▄▀ █▀▀▀▀▀█ █ ███ █ ██▀▄ ▄▄ ▀ █ ███ █ █ ▀▀▀ █ █▀██▄ ▄ █ ▀▀▀ █ ▀▀▀▀▀▀▀ █▄▀▄▀ █▄▀ ▀▀▀▀▀▀▀ ▀▄██▀▀▀ ▄▀ ▄▀█▀ ▄ ▀█▀▀▀▄ ▄▄█▀ ▀█▄ █ █▀▀ ▄█▀ ▀█ █▄▄█▄█▀█▀ █ ▀▀▀▀▄▀▀ ▀▄▀█▀ █ █▄▄▀▀▄ █▄█▀ ███▄█ ▀ ▀█ ▀ ▀ ▀▀▀▀▄▄ ▀▄▄ ▀█▀▀▀█▄▀ █▀▀▀▀▀█ ▄▄ ▄█▀ █ ▀ █▄▀██ █ ███ █ █▀█ ▀ ▀▀█████▀███ █ ▀▀▀ █ ▀ ██▀ ▄▄█▄ █▄▄▀ █ ▀▀▀▀▀▀▀ ▀ ▀ ▀▀▀▀▀▀
I've also tried quarter-blocks but the resulting image couldn't be recognised by my LineageOS phone's scanner, so that won't do. I wouldn't consider it a real concern, as columns are usually plentiful.
Sadly, half-blocks are missing from the portable Alternative Character Set, so having the terminal run in Unicode mode is basically a requirement here. This is also the reason why frameworks tend to use ugly full-block vertical shadows.
(Also worth mentioning are Unicode Braille Patterns, which may be misused to divide one cell into eight monochrome "subpixels", however note that some fonts may break this rendering.)
Terminals can have varying degrees of colour support, ranging from none to 24-bit true color.
True color is surprisingly supported by most terminal emulators now, however it's not easy to detect it reliably, as the experimental "Tc" and "RGB" terminfo entries are far from ubiquitous (you have to change TERM yourself to include "-direct" for the latter), COLORTERM isn't usually forwarded through ssh, and DECRQSS is sparsely implemented. Making ncurses use this full range is also tricky, and you can't usually get the lowest ~8 shades of blue because they share space with the basic palette. Hopefully colour number zero will be true black.
256-colour or 88-colour support is declared by the terminfo for your TERM, which needs to be set so that it includes "-256color" or "-88color" in its name. That isn't always the default. There is a direct mapping from the full 24-bit palette to these 256-colour or 88-colour indexed ones, as they contain an RGB cube with well-defined values, as well as a few more shades of grey. This is where predictability ends.
The lowest 16 colours, the common subset, can be basically anything. Each terminal defines it differently, and users like to change them according to their own liking, so you can't even rely on the hue, or expect text to show with acceptable contrast. With some luck, you may be able to read the colour values out, or even change them temporarily.
It's also worth mentioning that the default colours for the foreground and background may be arbitrary as well, and do not have to correspond with any indexed colour at all. But you may teach ncurses to treat them as index −1.
If you're particularly unlucky, the terminfo only declares 8 colours. In that case, you may usually still reach the brighter shades, however this requires some trickery and leaps of faith. Nonetheless: the "bold" (often) and "blink" (rarely) attributes can get you a bright foreground or background, respectively. And if the latter doesn't do that, the "inverse" attribute usually transplants brightness from the foreground to the background, and vice versa.
Purely monochromatic terminal emulators are rare, though it's not a bad idea to support a black-and-white mode in your applications. And to respect the NO_COLOR environment variable, while you're at it.
Work in progress.
ncurses, S-Lang, libtickit, ... https://midnight-commander.org/ticket/3264
Work in progress.
There is a reduced line drawing set available in curses that can be used to draw shapes. Better results can be achieved with Unicode, e.g., to get finer precision scrollbars.
Work in progress.
Amongst the more conventional, emulating GUIs:
Amongst the more manual:
Various applications have their own custom UIs. Therein lies pain.
As you can see, there's complexity everywhere you look. GUIs, by comparison, can even seem trivial, especially if you take something streamlined such as Win32. On Linux, with X11 and Wayland, you meet a different bunch of problems, yet the jump in complexity isn't as big as one might expect.
The true problem seems to be this: we are trying to make terminal applications too nice, too powerful, to have them do and integrate with things before unimagined, and the infrastructure to enable that tends to be added in ad hoc, hacky, imperfect ways, since the ecosystem is so incredibly fractured and weighed down by backwards compatibility.
Is it worth it in the end? Wouldn't the effort be better spent in improving the GUI side of things, instead of trying to fetishise the Unix terminal?
After all, terminals don't have to be confined by a rectangular grid and ancient artefacts. Even if you desire to keep some of the conveniences inherent to the interface, the two "worlds" can be merged. Consider Oberon. Consider Plan 9, with its 9P and /dev/draw. Take inspiration, explore, build better things. Stop wasting time trying to make pigs fly. Replace the pigs.
Related reading: The dawn of a new command line interface.
If you're interested in reading more on the topic of making terminals do things they weren't designed for, read the Notcurses book. Nick is much more headstrong than I am.
| urxvt 9.26 |
xterm 353 |
VTE 2.91 |
st 0.8.2 |
pterm 0.73 |
Konsole 19.12.3 |
mlterm 3.8.9 |
alacritty 0.5.0 |
termux 0.113 |
Terminal 2.12 (443) |
iTerm2 3.4.12 |
|
|---|---|---|---|---|---|---|---|---|---|---|---|
| Default TERM | rxvt-unicode-256color | xterm | xterm-256color1 | st-256color | xterm1 | xterm-256color1 | mlterm | alacritty | xterm-256color1 | xterm-256color1 | xterm-256color1 |
| Program version in the environment |
– | XTERM_ |
VTE_ |
– | – | KONSOLE |
MLTERM | – | – | TERM |
LC_TERMINAL TERM |
| DECRQM | • | • | • | – | – | –2 | • | – | • | –2 | • |
| DECRQSS SGR | – | •3 | – | – | – | – | •4 | – | – | – | • |
| Colours | 2565 | 24-bit | 24-bit | 24-bit | 24-bit | 24-bit | 24-bit6 | 24-bit | 24-bit | 256 | 24-bit |
| Get/set colour | •7/• | •/• | •/• | –/• | •/•8 | –/– | •/• | –/• | –/• | •/• | •/• |
| Bold is bold/bright | •/• | •/• | •/–9 | •/• | –9/• | •/• | •/• | •/–9 | •/• | •/–9 | •/•9 |
| Blink attribute | bg or blinks10 | blinks | blinks | blinks | bg | blinks | blinks11 | –12 | ≡bold | blinks | –9 |
| Italic text | • | • | • | • | – | • | • | • | • | • | • |
| Overline attribute | – | – | • | – | – | • | • | – | – | – | – |
| Underline colour | – | – | • | – | – | – | – | – | – | – | – |
| DECRQSS DECSCUSR | – | • | • | – | – | – | • | – | – | – | • |
| Bar cursor | • | • | • | won't blink |
– | • | • | won't blink |
won't blink | • | • |
| w3mimgdisplay | • | • | – | frail13 | frail13 | frail13 offset14 |
• | frail13 | N/A | N/A | N/A |
| Sixel graphics | – | –9 | – | – | –15 | – | • | – | – | –15 | • |
| Mouse protocol | 1005 1006 1015 | 1005 1006 1015 |
1006 | 1006 | 1006 1015 | 1005 1006 1015 |
1005 1006 1015 | 1005 1006 |
1006 | 1005 1006 1015 | 1005 1006 1015 |
| Focus events | • | • | • | • | – | • | • | • | – | • | • |
| Get/set selection | –/– | –/–16 | –/– | –/•17 | –/– | –/– | –/– | –/• | –/• | –/– | –/–9 |
| Bracketed paste | • | • | • | • | • | • | • | • | • | • | • |
| Non-UTF-8 | •18 | luit19 | config20 | – | config20 | config20 | • | – | – | config20 | config20 |
TERM=xterm supporting features
that can't be detected via terminfo.
p is interpreted as separate input.
--vtcolor=true switch it is capable
of displaying a smooth ramp but by default it's in a "high color" mode.
enter_blink_mode in its custom terminfo file.
Reported.
enter_blink_mode in its custom terminfo file.
WINDOWID.
-lc switch. Natively, xterm only supports
UTF-8, and optionally also ISO Latin 1 and 9, which are encodings mostly
matching the first 256 codepoints of Unicode. luit can be run manually in other
terminals (or terminal multiplexers) as well, perhaps even wrapping the shell,
should you so desire. From my experience, it likes to cause problems. Mouse
mode 1005 is one of them, ACS is another.
-cs option, or inferred from the
X11 font! What a mess.
This table has been constructed according to real capabilities, not what the terminal emulators claim in their respective terminfo entries, which is only partial and often outdated information. Also note that some features can be configured, these were the defaults on the distribution.
See also another miniseries of terminal emulator comparisons: part 1, part 2. It is accompanied by a set of scripts (still falsely claiming mlterm uses VTE in the README, while it's an absolute champion, packed with features).
Then there's an extensive spreadsheet that evaluates a different subset of applications and doesn't specify versions. And a whole group of masturbating monkeys who try to write specifications for everything, a few decades too late.
I did not want to clutter my host system, so I used an Ubuntu 20.04 LTS VM to test the terminal emulators. Termux is from F-Droid, and luckily enough the last version on Play Store already contains the fix for a DECRQM issue I managed to report in time. I've also checked ConnectBot but that was a disappointment so huge that I didn't even bother. Terminal and iTerm2 have been run on macOS Monterey.
alacritty isn't currently present in Debian repositories and for the latest 0.5.0 version they stopped providing pre-built packages in their GitHub releases (for good reason, dependencies are problematic), though you can retrieve it from an unofficial PPA:
sudo add-apt-repository ppa:mmstick76/alacritty
sudo apt install rxvt-unicode xterm gnome-terminal stterm pterm konsole mlterm \
alacritty w3m-img git tcc libncurses-dev
Once you've installed all programs you want to test, use my partially automated tool:
sudo sed -i 's/^# \(cs_CZ.*\)/\1/' /etc/locale.gen sudo locale-gen git clone https://git.janouch.name/p/termtest.git echo Žluťoučký kůň | iconv -t latin2 > 8bit unset COLORTERM WINDOWID for term in urxvt "xterm -lc" st pterm konsole mlterm alacritty; do $term -e tcc "-run -lncurses" termtest/termtest.c "$term" LC_ALL=cs_CZ LANG=cs_CZ $term -e bash -c "cat 8bit; bash" done # GNOME Terminal is the only one that is non-conforming in something so basic gnome-terminal --wait -- tcc "-run -lncurses" termtest/termtest.c VTE
Maybe I'll finish this one day…
Comments
I'll pick up on new Hacker News, Lobsters, and Reddit posts, or you can send me an e-mail.
Hacker News
Lobsters